


Discrimination of Storage Time of White Tea Using Hyperspectral Imaging
-
摘要: 储藏年份是决定白茶经济价值的一大因素。为了实现快速便捷地判别白茶储藏年份,本文提出了基于高光谱成像技术判别分析白茶储藏年份的无损检测方法。通过对3、6、10年寿眉高光谱图像感兴趣区域光谱数据的提取,采用最小二乘平滑滤波、标准正态变换、归一化、多元散射校正预处理算法,并用支持向量机、偏最小二乘联合线性判定法、逻辑回归建模对不同预处理后的光谱数据进行判别分析。最后,通过分析混淆矩阵、精确率、召回率来评估模型性能。分析结果表明,经过标准正态变换预处理结合支持向量机所建立的模型判别效果最佳,训练集和测试集的精确率分别为90.83%和86.02%。由此可见,利用高光谱成像技术对白茶储藏年份进行快速无损的判别具有一定的可行性。Abstract: The storage time is a main factor determining the value of white tea. To discriminate the storage time rapidly and nondestructively, a new method was applied in this paper. First, hyperspectral image data were captured from Shoumei of 3, 6 and 10 years storage time. Second, four kinds of algorithms were applied to preprocess the original data, savitzky-golay Filter, standard normal variate, minmaxscaler, and multiplicative scatter correction. Third, support vector machine, partial least squares with linear discriminant analysis and logistic regression were built based on the data of the full spectra. Finally, the best combination of preprocessing algorithm and model could be found by comparing the confusion matrix, precision and recall. The results showed that the best classification performances were obtained with the support vector machine after the pretreatment of standard normal variate. The precision of the calibration sets was 90.83%, and that of the prediction sets was 86.02%. Therefore, it is possible to use hyperspectral imaging to discriminate white tea of different storage time in tea industry.
-
Keywords:
- white tea /
- hyperspectral imaging /
- discriminant analysis /
- storage time
-
白茶是我国六大茶类之一,主要产区在福建福鼎、政和、松溪、建阳、云南景谷等地。根据原料的嫩度不同,白茶可分为白毫银针、白牡丹、寿眉和贡眉。萎凋和干燥这两道工序形成了白茶独特的品质特征和生物活性。研究表明,白茶具有许多强大的生物活性,包括抗氧化、抗炎、抗癌、抗菌和神经保护活性[1-5]。而在茶叶销售市场中,长期储存的白茶更受到广大消费者的喜爱和追捧,有着“一年茶,三年药,七年宝”的说法。有研究表明[6],白茶在储藏过程中,其化学品质成分会发生改变,与新白茶相比,储藏白茶的醇含量更低,碳氢化合物含量更高。Ning等[7]发现儿茶素和氨基酸的含量随着储藏年份的延长呈相似的下降趋势,而没食子酸的含量则增加。相比之下,由茶氨酸和儿茶素在储藏过程中形成的7种新化合物8-C-N-乙基-2-吡咯烷酮(8-C N-ethyl-2-pyrrolidi-none-substituted flavan-3-ols,EPSFs)取代黄烷-3-醇显著增加,其含量与储藏年份呈正相关[8]。随着消费者对储藏白茶的喜爱的增加,市面上也出现了储藏年份造假的现象,但当下关于白茶储藏年份预测的研究报道极少。Dongchao Xie等[9]对白茶中24种储藏相关化合物进行了绝对定量分析和线性回归,分析表明基于EPSFs的5个指标组合对白茶储藏年份具有较好的判别能力,其中模型和测试集的相关系数分别为0.9294和0.8812。该模型对于储藏年份小于10年的白茶,预测和实际储藏年份之间的误差在−1.75~1.84年之间,尚不能满足快速精确判别白茶年份的需求。
光谱技术的发展为快速、准确地进行茶叶品控检测提供了基础,近年来较多研究集中在近红外光谱技术在茶叶领域中的应用。刘鹏[10]提出采用局部线性嵌入法和拉普拉斯特征映射法对近红外光谱数据进行非线形流形降维处理,从而提高不同海拔茶叶品质的鉴别精度。Wang等[11]利用微型近红外光谱仪预测了红绿茶的判别模型,基于标准正态变量的支持向量机模型对两类茶叶中的儿茶素和咖啡因都有较高的判别能力。刘洪林等[12]对利用近红外光谱技术结合感官审评结果建立多个预测模型,其预测性能优,为客观评价功夫红品质提出新方法。李春霖[13]采用化学计量方法和近红外光谱技术对龙井茶的感官和化学品质评价进行了系统性研究,建立龙井茶鲜味和涩味的定性预测模型,预测准确率达75.18%。
相较于近红外光谱技术,高光谱成像技术是一种更高效、无损的检测技术。近红外光谱技术对待检测的样本有一定的要求,例如磨碎过筛,而高光谱成像技术则不需要。并且高光谱成像技术是成像技术和光谱技术的结合体,故可以同时获得待测样品的光谱信息和空间信息,以此检测样品的内外品质。目前高光谱成像技术在茶叶领域的研究主要集中在茶叶等级判别和茶类判别。于英杰等[14]利用高光谱技术对不同等级的铁观音进行判别,结合支持向量机的模型对未知的铁观音茶样正确判别率可达92.86%。李晓丽等[15]结合高光谱成像仪和高效液相色谱法,建立光谱与表没食子儿茶素没食子酸酯(epigallocatechin gallate,EGCG)浓度之间的回归模型,其最优回归模型的决定系数达到0.905。李瑶等[16]以蒙顶黄芽、竹叶青、甘露茶叶为实验对象,利用高光谱成像技术结合支持向量机建立茶叶品种判别模型和茶叶等级判别模型,其精确率分别达到了100%和96.67%。Guangxin Ren等[17]利用近红外高光谱成像结合多决策树的方法,对祁门工夫红茶进行了品质和等级判别,比较了三种不同类型的监督决策树算法,其中基于数据融合的细树(fine tree, FT)模型预测效果最好,红茶品质的评价正确率达到93.13%。Zhiqi Hong等[18]采用380~1030和874~1734 nm两个光谱范围的高光谱成像系统对6个产地的龙井茶单叶进行了产地判别,建立了支持向量机和偏最小二乘判别分析模型,在两个光谱范围内均获得了良好的分类性能,校正集和预测集的总体分类精确率均在84%以上。
鉴于白茶储藏年份判别的研究报道较少以及高光谱成像技术的优点,本文探讨高光谱成像技术在白茶储藏年份判别中的应用,在450~998 nm光谱范围采集白茶的高光谱图像并建模分析,尝试为白茶储藏年份快速检测提供理论基础。
1. 材料与方法
1.1 材料与仪器
实验样本 均来自福建省福鼎市(北纬26°52′~27°26′,东经119°55′~120°43′)12家茶叶企业。选取的白茶样本等级均为寿眉,原料品种均为福鼎大毫。实验样本的储藏条件与白茶的一般储藏条件基本一致,实验前样本均储藏在室温25 ℃,通风干燥的茶叶储藏室中。在实验当月2020年8月,将生产日期在2017年5月~10月、2014年5月~10月、2010年5月~10月的样本储藏时间分别归为3、6、10年,样本数量分别为160、156、148,每份样本约为15 g。
Q285成像光谱仪 来自德国品牌Cubert;AZ-D100卤素灯 来自德国品牌Osram。为避免图像采集时环境光的干扰:4个75 W卤素灯对称安装在暗箱侧部,保证整个视场光照均匀,电控升降台安装在暗箱底部。成像光谱仪通过网线与计算机相连,以控制数据的采集和传输[19-20]。Q285采用能在千分之一秒内获得样本高光谱图像立方体数据的画幅式成像技术,相比于传统的推扫式成像技术,不需要配备电动位移平台,其数据采集过程更加快速、稳定。Q285的主要技术参数如下:光谱范围为450~998 nm,采样间隔4 nm,通道125,镜头焦距23 nm,像素分辨率1000×1000,数字分辨率14 bit。
1.2 光谱采集
采集高光谱图像前的准备工作:实验前30 min打开光源进行预热,将寿眉样本均匀平铺在直径150 mm、高度20 mm的培养皿中,培养皿预先内置反射率近似为零的黑色橡胶,以免影响实验数据。
打开高光谱图像采集软件的操作界面,采集寿眉样本的高光谱图像。使用HSI Analyzer(ISUZU optics,中国台湾)软件对高光谱图像进行白板与暗电流校正。然后,利用ENVI 5.1(Exelis VIS,美国)软件分析寿眉的光谱特征,确定分割阈值,将背景置0,并使用Spectral Python 0.21,scikit-learn 0.23.1,numpy 1.18.1,pandas 1.0.3做后续光谱数据分析。
1.3 数据处理
1.3.1 光谱提取和样本划分
由于寿眉样本等级基本一致,且叶梗芽随机分布,颜色花杂,故高光谱采集到的图像数据对寿眉分类并无实际意义,本文只分析光谱数据。高光谱图像在采集过程中会受到多种因素的干扰,因此高光谱图像的去噪尤为重要[21]。为了尽可能保留光谱的主要特征,同时又能去除光谱中的噪音,本文采用数学形态学中的二值形态学对采集到的寿眉样本图像进行降噪处理,利用开运算和闭运算将图像上孤立的小点和毛刺去掉,填平小孔,并保持总体的位置和形状不变。
因为寿眉样本的不同部位,如梗、叶、芽所含的内含物质成分差异明显,故每个像素点之间的光谱数据差异较大。为解决这一问题,如图1所示,本文采用的方法是在样本区域内随机选取100个20×20像素的感兴趣区域(Region of Interest, ROI),其中一个像素点包含一条光谱信息,再计算ROI内所有像素点的平均光谱作为建立模型的光谱数据进行下一步分析。
![]() 图 1 寿眉样本高光谱图像数据采集示意图注:(a)高光谱图像去噪后的原图;(b)在样本区域内随机选取100个ROI示意图;(c)随机提取后得到的100个ROI。Figure 1. Sketch of data acquisition
图 1 寿眉样本高光谱图像数据采集示意图注:(a)高光谱图像去噪后的原图;(b)在样本区域内随机选取100个ROI示意图;(c)随机提取后得到的100个ROI。Figure 1. Sketch of data acquisition为了防止同一个样本的方块数据点同时出现在训练集和测试集,本实验以每个寿眉样本的100个ROI作为一个单位进行判别分析。本次实验一共464个寿眉样本,共采集到46400个ROI,464个数据组。为了防止训练集过拟合,同时防止因为训练集测试集划分引起的精确率的误差,本文采用5折交叉验证法以增强模型的泛化能力,即进行5次随机划分,最后取各次结果平均值来评估模型效果。每一次都采用随机挑选法选取371个数据组作为训练集,剩余93个数据组作为测试集。
1.3.2 四种预处理方法
因为电噪音、光散射、基线漂移、光程变化等因素的干扰强度较大,还需要对光谱数据做必要的预处理。本文采用4种光谱预处理算法:最小二乘平滑滤波(Savitzky-Golay Filter,SGF)、归一化(MinmaxScaler,Minmax)、多元散射校正(Multiplicative Scatter Correction,MSC)、标准正态变换(Standard Normal Variate,SNV)。后续实验分别建立不同预处理后的光谱与储藏时间的不同判别模型,通过对比不同预处理后的建模结果,确定最佳处理组合。
1.3.2.1 最小二乘平滑滤波(SGF)
Savitzky-Golay滤波器广泛地运用于数据平滑去噪,是一种基于局域多项式最小二乘法拟合的滤波方法,其最大特点在于去除噪声的同时可以保留信号的形状、宽度不变[22]。该方法应用于光谱数据的主要作用是消除随机噪声,提高信噪比。
1.3.2.2 标准正态变换(SNV)
粒子大小、散射和多重共线性是漫反射光谱分析中长期存在的问题。这些效应的乘性组合是阻碍解释漫反射光谱的主要因素。样品粒子大小是影响方差的主要因素,而由化学成分引起的方差很小。SNV可有效地消除散射、粒径的乘性干扰和多重共线性[23]。该算法处理光谱数据的基本思想是:假设每一条光谱中各波长点的反射强度应符合正态分布,再对每一条原始光谱数据进行标准正态化处理使得校正后的光谱数据均值为0,标准差为1。具体如以下公式:
x′=x−μσ (1) 式中:x是原始光谱数据;x′是经过标准正态变换后的光谱数据;μ为平均值;σ为原始光谱数据的标准偏差。
1.3.2.3 归一化(Minmax)
Minmax的原理与SNV相似,目的都是为了方便处理数据,使得整个数据分布更加均匀,且两者都能使模型运行时的收敛速度加快[24]。Minmax与SNV的区别在于,Minmax是将训练集中某一列数值特征(假设是第i列)的值缩放到0到1之间或者−1到1,从而降低特异样本数据导致的不良影响。计算公式如下:
x″=xi−min(xi)max(xi)−min(xi) (2) 式中:
x″ 是经过Minmax变换后的光谱数据;xi 是第i列的任一原始光谱数据;max(xi) 是该列中最大值;min(xi) 是最小值。1.3.2.4 多元散射校正(MSC)
MSC主要用来消除固体颗粒大小、表面散射对漫反射的影响。多元散射校正通过校正每个光谱的散射来消除颗粒分布不均匀及颗粒大小产生的影响,增强了与成分含量相关的光谱吸收信息[25]。广泛应用于固体漫反射光谱。使用该方法的前提是建立一个待测样品的“理想光谱”,而实际上并不存在“理想光谱”。该光谱的特点是样品中的成分含量与其满足线性关系,然后将该光谱作为标准对其他样品的光谱进行修正,其中包括基线平移和偏移校正。在实际应用中,经常将所有光谱的平均光谱视为一个理想的标准光谱。
1.3.3 三种判别模型
本文通过混淆矩阵、精确率、召回率对建立的模型进行评估。以最简单的二分类问题为例,预测结果可分为四类,分别是:原本为正例的样本被预测为正类(True Positive, TP)或负类(False Negative, FN),原本为负例样本被预测为负类(True Negative, TN)或正类(False Positive, FP)。精确率是针对总体预测结果而言的,它表示的是所有预测正确的样本占总观测值的比重,若用P表示精确率(Precision),则:
P=TPTP+FP (3) 而召回率是针对原来的样本而言的,它表示的是样本中的正例被预测正确的比例,若用R表示召回率(Recall),则:
R=TPTP+FN (4) 1.3.3.1 支持向量机
支持向量机(Support vector machine,SVM)是将低维空间线性不可分的数据映射到高维,利用支持向量用来寻找一个最优分类超平面,使得不同类别的边缘数据点之间的距离最大化,使得分类器的泛化能力最强,从而实现最优的二分类或多分类。SVM的核心是将高维特征空间中的内积运算转化为低维空间中的内积核函数,以实现数据在经历非线性转化后的线性划分[26]。核函数是支持向量机映射数据的重要手段[27]。在光谱数据分析中,径向基函数(RBF)因其较强的非线性问题处理能力而成为应用最广泛的核函数。本文以径向基函数作为核函数,采用网格搜索法确定支持向量机的超参数(惩罚系数c和核宽度g)。
1.3.3.2 偏最小二乘法联合线性判别
偏最小二乘法(Partial Least-square Method,PLS)是一种基于特征变量的回归方法,其实质是按照协方差极大化准则,在分解自变量变量数据矩阵X的同时,也在分解因变量数据矩阵Y,并且建立相互对应的解释隐变量与反应隐变量之间的回归关系方程[28]。偏最小二乘回归的成分之间是相互正交的,这在一定程度上消除了多重线性相关性。线性判别(Linear discriminant analysis,LDA)分类器是一种监督学习的数据降维方法,该方法的核心是将输入变量空间投影到最佳鉴别矢量空间,达到样本在投影后的矢量空间中“类内方差最小,类间方差最大”的目的,即投影后每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。之后通过计算待测样本与各中心的距离,待测样本的类别即为距离最短的[29]。
1.3.3.3 逻辑回归
逻辑回归(Logistic Regression, LR)是在线性回归的基础上构建一种分类模型,是对于特征的线性组合来拟合真实标记为正例的概率的对数几率,其公式可表示为:
(lny1−y=wx+b) (5) 式中:w,b均为参数。
LR多应用于二分类问题,一个事件发生的机率定义为事件发生的概率与不发生的概率的比值,设p=P(y=1|x,w),那么事件的几率是p/1−p,其对数几率是:
lnp1−p=lnP(y=1|x,w)1−P(y=1|x,w)=wx+b (6) 可以看出,输出类别1的对数几率函数是输入x的线性函数,对数几率函数是Sigmoid函数的重要代表[30]。对于多分类问题,LR的方法是将多分类转化为所有的多个二分类问题,然后对样本,再依次进行二分类[31]。
2. 结果与分析
2.1 光谱分析
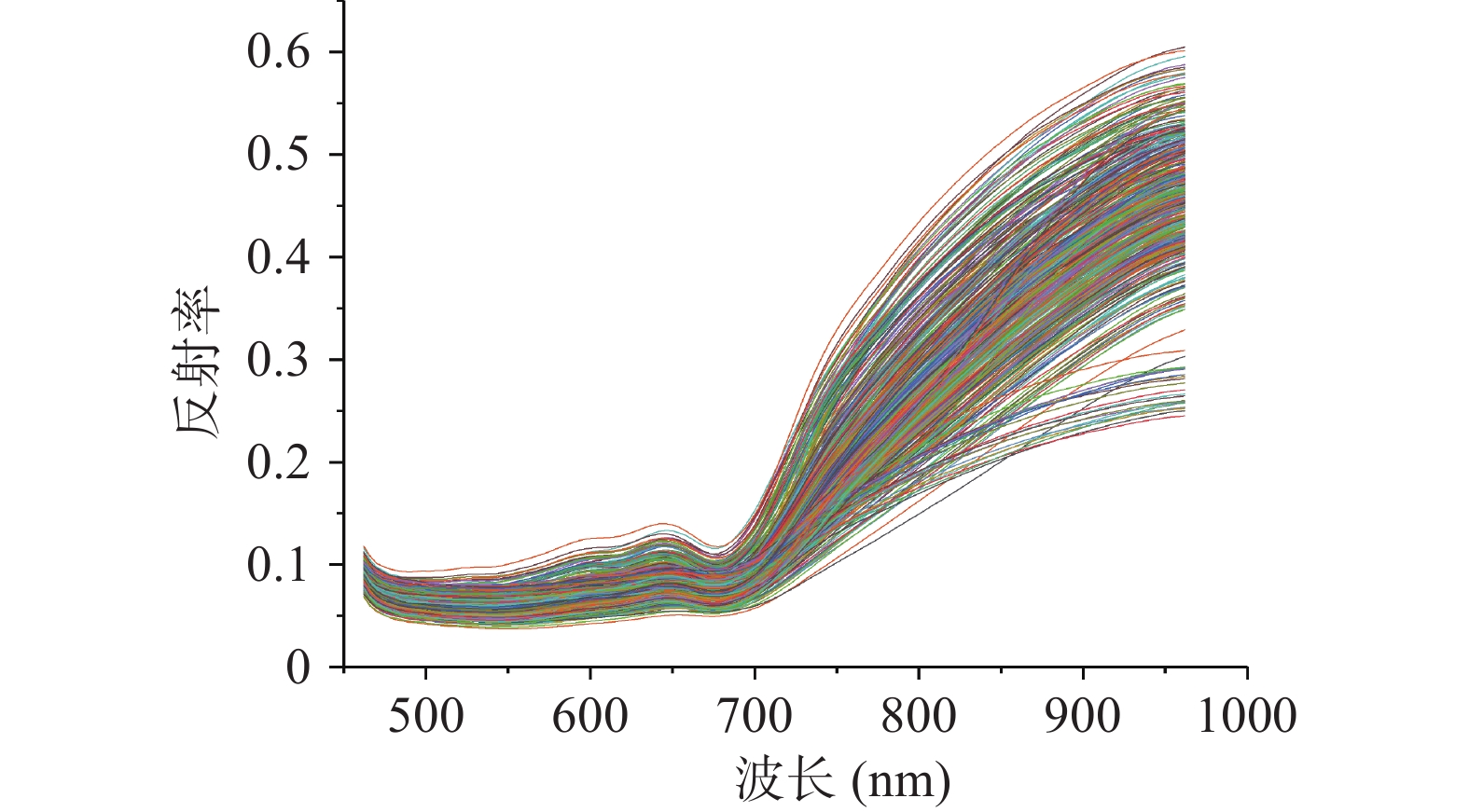
由于三个储藏年份的寿眉样本的光谱曲线在头尾处存在较大的随机误差,首先除去全波段中450~461 和963~998 nm的首尾噪声,以获得波段范围为462~962 nm内的126个波段的光谱数据进行后续分析。统计每个样本的光谱数据并作图,结果如图2所示。根据图2可知,650~700 nm处存在一个波谷,可能是因为叶绿素在663 nm处有较大的吸光系数,李晓丽等[15]利用高光谱成像实现茶叶中EGCG可视化研究中也有类似研究现象。700~900 nm处寿眉样本对光谱的反射急剧上升,是因为寿眉对近红外波段吸收较少。每条光谱曲线的形状类似,说明寿眉样本内部的内含成分大致相同。随着储藏时间的变化,寿眉的内含成分的含量发生变化,导致在相同的波段有不同的反射率,这也为寿眉储年份测定奠定了客观基础。
2.2 预处理效果
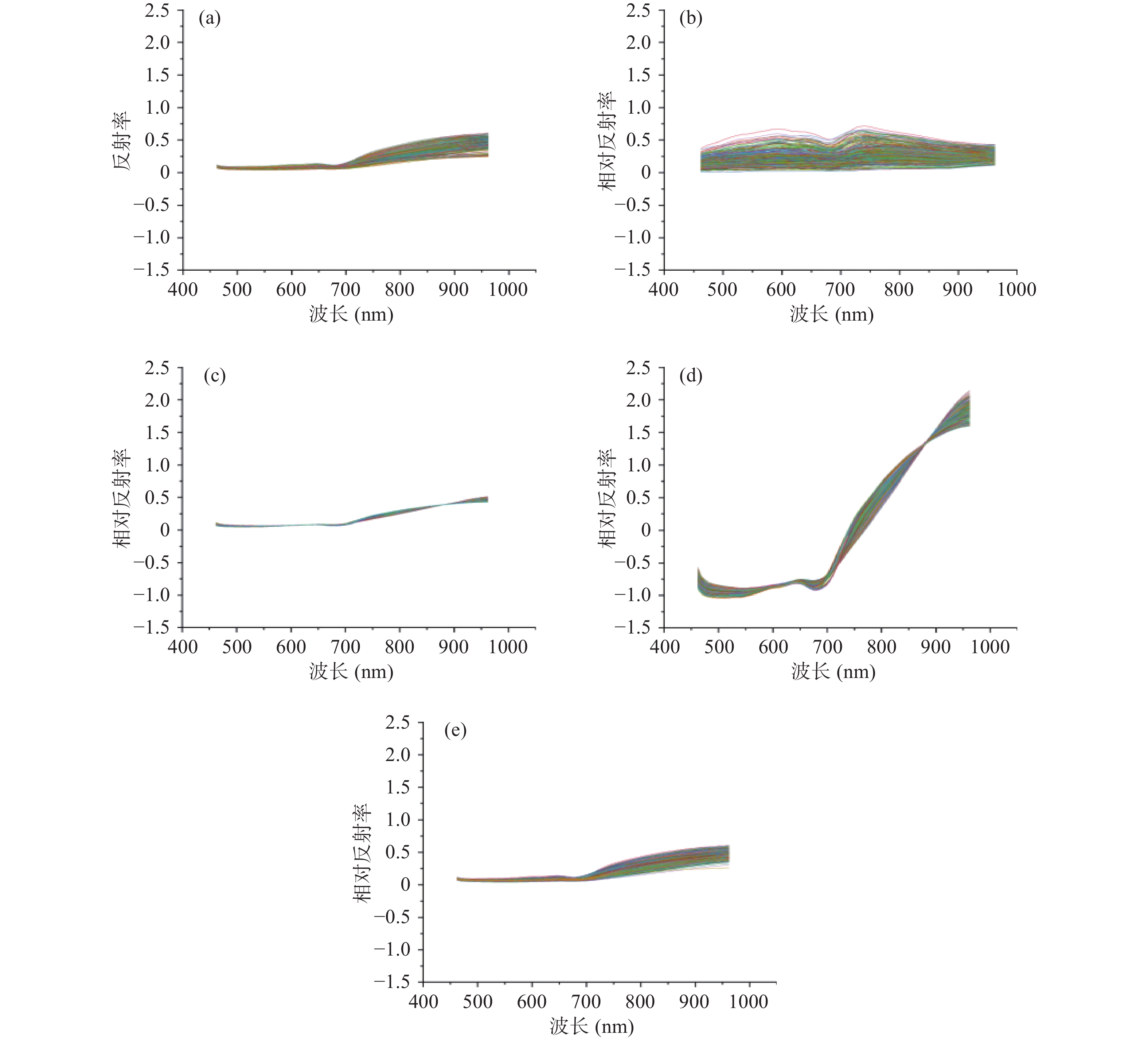
由图3可知,在同一坐标系下,除了SNV预处理后的光谱,其余光谱的相对反射率均在0以上。由1.3.2.3中的公式可知,SNV预处理后的相对反射率值为原始反射率减去该波段所有反射率的平均值再除以原始光谱的标准偏差后得到,所以相对反射率会出现负值。从光谱变化情况可知,相比于其余预处理,SNV预处理后的光谱在不同波段的相对反射率变化较大。从光谱分布情况可知,MinMax预处理后的光谱分布相比于原始光谱更为离散;MSC预处理后光谱分布相比于原始光谱更为集中,而SGF预处理前后差异不明显。光谱预处理后的具体建模效果还需结合建模结果进一步分析。
![]() 图 3 预处理效果图注:(a)原始光谱;经MinMax(b),MSC(c),SNV(d),SGF(e)预处理后的光谱。Figure 3. Spectra of all samples after being preprocessed
图 3 预处理效果图注:(a)原始光谱;经MinMax(b),MSC(c),SNV(d),SGF(e)预处理后的光谱。Figure 3. Spectra of all samples after being preprocessed2.3 建模结果分析
2.3.1 SVM建模结果
表1是SVM建模分析结果,表2是该模型下的最优处理即SNV-SVM处理后得到的混淆矩阵。从表1可以看出,经过SNV预处理后的建模结果最优,训练集和测试集的精确率明显高于其他预处理,分别为90.83%和86.02%。其中没有经过预处理的建模效果在两个数据集上的表现与经过Minmax预处理后的差异较小,说明原始光谱分布较为均匀,导致该预处理在SVM模型中效果一般。从表2混淆矩阵中可以看出,SNV-SVM处理组合对于训练集不同年份寿眉样本的预测效果差异不大,但对于测试集中的预测效果差异明显,其中3、10年寿眉的召回率接近,分别为90.32%、89.29%,而6年寿眉的召回率只有79.41%。
表 1 SVM建模分析结果Table 1. Results of SVM modeling analysis预处理算法 训练集精确率(%) 测试集精确率(%) 无 83.47 77.58 Minmax 81.67 77.34 SGF 87.31 83.29 SNV 90.83 86.02 MSC 84.43 80.67 表 2 SNV-SVM处理的混淆矩阵Table 2. The confusion matrix in SNV-SVM model2.3.2 PLS-LDA建模结果
表3是PLS-LDA建模分析结果,表4是该模型下的最优处理即SNV-PLS-LDA处理后得到的混淆矩阵。由表3可见,经过SNV预处理之后的建模结果最佳,训练集和测试集中的精确率分别为80.05%和74.19%;而经过部分预处理后的建模结果相较于无预处理并没有明显的提高。在PLS-LDA模型中,与SVM建模结果类似,不经过预处理与经过Minmax预处理后的建模结果几乎一致;不经过预处理的建模结果比经过SGF和MSC预处理的建模结果更好,可见原始光谱的噪声较小、基线漂移不明显,预处理可能会造成有效信息的损失。从表4混淆矩阵中可见,经过SNV预处理后,10年的寿眉样本的精确率最高,但召回率最低,在测试集中分别为86.67%、66.67%;3年的寿眉样本情况则相反,在测试集中的精确率和召回率分别为62.50%、80.00%。
表 3 PLS-LDA建模分析结果Table 3. Results of PLS-LDA modeling analysis预处理算法 训练集精确率(%) 测试集精确率(%) 无 77.12 70.73 Minmax 77.17 70.73 SGF 75.03 69.11 SNV 80.05 74.19 MSC 75.29 63.41 表 4 SNV-PLS-LDA处理的混淆矩阵Table 4. The confusion matrix in SNV-PLS-LDA model训练集 测试集 年份(年) 3 6 10 精确率(%) 召回率(%) 3 6 10 精确率(%) 召回率(%) 3 91 9 9 71.09 83.49 20 2 3 62.50 80.00 6 17 101 4 80.80 82.79 5 23 1 74.19 79.31 10 20 15 105 88.98 75.00 7 6 26 86.67 66.67 总值 80.05 80.05 74.19 74.19 2.3.3 LR建模结果
表5是LR建模分析结果,表6是该模型下的最优处理即Minmax-LR处理后得到的混淆矩阵。从表5可知,与PLS-LDA建模结果类似,不经过预处理的建模结果和SGF、MSC预处理后的建模结果差异较小。但与其他两种模型不同的是Minmax相比于其他预处理在LR模型中的表现最佳,训练集和测试集的精确率分别为84.64%和78.50%,这与LR模型本身对样本分布的均匀度更为敏感有关。从表6混淆矩阵中可以看出,Minmax模型对三个储藏年份的寿眉样本判别存在差异,且在两个数据集中都对3年寿眉样本的判别最佳,6年其次,10年最差。
表 5 LR建模分析结果Table 5. Results of LR modeling analysis预处理算法 训练集精确率(%) 测试集精确率(%) 无 77.06 73.45 Minmax 84.64 78.50 SGF 77.06 71.22 SNV 83.69 71.39 MSC 77.06 74.09 表 6 Minmax-LR处理的混淆矩阵Table 6. The confusion matrix in Minmax-LR model训练集 测试集 年份(年) 3 6 10 精确率(%) 召回率(%) 3 6 10 精确率(%) 召回率(%) 3 113 8 4 88.28 90.40 27 4 2 84.38 81.82 6 5 103 16 82.40 83.06 0 24 6 77.42 80.00 10 10 14 98 83.05 80.33 5 3 22 73.33 73.33 总值 84.64 84.64 78.50 78.50 2.3.4 建模结果小结
从表7可以得出,SVM模型对于寿眉样本的判别效果要明显优于PLS-LDA、LR模型,其中最佳处理组合SNV-SVM在训练集和测试集的精确率分别为90.83%、86.02%。四种预处理方法中,SNV在三种判别模型中的表现较好,Minmax其次,SGF和MSC表现一般。该结果与原始光谱数据特点相关,原始光谱数据所受到随机噪声和基线漂移的影响都较小,SGF和MSC预处理后可能降低原始光谱中的有效信息,导致后续的建模效果相较于无预处理并不明显,在PLS-LDA模型中甚至更差。
表 7 三种判别模型的最优处理汇总Table 7. Results of three discriminant models with their best preprocessing algorithm处理组合 训练集精确率(%) 测试集精确率(%) SNV-SVM 90.83 86.02 SNV-PLS-LDA 80.05 74.19 Minmax-LR 84.64 78.50 3. 结论
本文通过高光谱成像技术获得450~998 nm波段范围内的高光谱数据对储藏年份为3、6、10年的寿眉样本进行无损检测研究。采用Minmax、SGF、SNV、MSC 4种算法来对寿眉原始光谱数据进行预处理,并分别建立SVM、PLS-LDA、LR判别模型。建模结果表明,相较于线性模型PLS-LDA、LR,非线性模型SVM对于寿眉样本的高光谱数据有更好的判别效果,说明光谱数据和白茶储藏年份之间的关系更可能是一个非线性关系,这与白茶中多种内含成分在储藏过程中不断发生复杂的化学变化有关。本文所建立的SNV-SVM处理组合针对3、6、10年这三个年份的寿眉有较高的判别精确率以及较强的泛化能力,而对于判别其他品类和其他年份的白茶还需后续进一步研究。
-
![]()
图 1 寿眉样本高光谱图像数据采集示意图
注:(a)高光谱图像去噪后的原图;(b)在样本区域内随机选取100个ROI示意图;(c)随机提取后得到的100个ROI。
Figure 1. Sketch of data acquisition
![]()
图 3 预处理效果图
注:(a)原始光谱;经MinMax(b),MSC(c),SNV(d),SGF(e)预处理后的光谱。
Figure 3. Spectra of all samples after being preprocessed
表 1 SVM建模分析结果
Table 1 Results of SVM modeling analysis
预处理算法 训练集精确率(%) 测试集精确率(%) 无 83.47 77.58 Minmax 81.67 77.34 SGF 87.31 83.29 SNV 90.83 86.02 MSC 84.43 80.67  下载: 导出CSV
下载: 导出CSV
表 3 PLS-LDA建模分析结果
Table 3 Results of PLS-LDA modeling analysis
预处理算法 训练集精确率(%) 测试集精确率(%) 无 77.12 70.73 Minmax 77.17 70.73 SGF 75.03 69.11 SNV 80.05 74.19 MSC 75.29 63.41
下载: 导出CSV
表 4 SNV-PLS-LDA处理的混淆矩阵
Table 4 The confusion matrix in SNV-PLS-LDA model
训练集 测试集 年份(年) 3 6 10 精确率(%) 召回率(%) 3 6 10 精确率(%) 召回率(%) 3 91 9 9 71.09 83.49 20 2 3 62.50 80.00 6 17 101 4 80.80 82.79 5 23 1 74.19 79.31 10 20 15 105 88.98 75.00 7 6 26 86.67 66.67 总值 80.05 80.05 74.19 74.19
下载: 导出CSV
表 5 LR建模分析结果
Table 5 Results of LR modeling analysis
预处理算法 训练集精确率(%) 测试集精确率(%) 无 77.06 73.45 Minmax 84.64 78.50 SGF 77.06 71.22 SNV 83.69 71.39 MSC 77.06 74.09
下载: 导出CSV
表 6 Minmax-LR处理的混淆矩阵
Table 6 The confusion matrix in Minmax-LR model
训练集 测试集 年份(年) 3 6 10 精确率(%) 召回率(%) 3 6 10 精确率(%) 召回率(%) 3 113 8 4 88.28 90.40 27 4 2 84.38 81.82 6 5 103 16 82.40 83.06 0 24 6 77.42 80.00 10 10 14 98 83.05 80.33 5 3 22 73.33 73.33 总值 84.64 84.64 78.50 78.50
下载: 导出CSV
表 7 三种判别模型的最优处理汇总
Table 7 Results of three discriminant models with their best preprocessing algorithm
处理组合 训练集精确率(%) 测试集精确率(%) SNV-SVM 90.83 86.02 SNV-PLS-LDA 80.05 74.19 Minmax-LR 84.64 78.50
下载: 导出CSV
-
[1] Liu L, Liu B, Li J, et al. Responses of different cancer cells to white tea aqueous extract: Response to white tea aqueous extract[J]. Journal of Food Science,2018,83(10-12):2593−2601.
[2] Orner G A. Suppression of tumorigenesis in the Apcmin mouse: Down-regulation of β-catenin signaling by a combination of tea plus sulindac[J]. Carcinogenesis,2003,24(2):263−267. doi: 10.1093/carcin/24.2.263
[3] Rasolifard M H, Nozohor Y. The effect of aqueous extract of white tea on the levels of antioxidant enzymes of rats' liver tissue exposed to arsenic[J]. Journal of Ilam University of Medical Sciences,2018,25(5):146−153. doi: 10.29252/sjimu.25.5.146
[4] Sangeeta Rangi, Sunil Kumar Dhatwalia, Priti Bhardwaj, et al. Evidence of similar protective effects afforded by white tea and its active component ‘EGCG’ on oxidative-stress mediated hepatic dysfunction during benzo(a)pyrene induced toxicity[J]. Food and Chemical Toxicology,2018,116:281−291. doi: 10.1016/j.fct.2018.04.044
[5] Camouse Melissa M, Domingo Diana Santo, Swain Freddie R, et al. Topical application of green and white tea extracts provides protection from solar-simulated ultraviolet light in human skin[J]. 2009, 18(6): 522−526.
[6] 刘琳燕, 周子维, 邓慧莉, 等. 不同年份白茶的香气成分[J]. 福建农林大学学报(自然科学版),2015,44(1):27−33. [Liu L Y, Zhou Z W, Deng H L, et al. Analysis of the aromatic components in white tea produced in different years[J]. Journal of Fujian Agriculture and Forestry University (Natural Science Edition),2015,44(1):27−33. [7] Ning J M, Ding D, Song Y S, et al. Chemical constituents analysis of white tea of different qualities and different storage times[J]. European Food Research and Technology,2016,242(6):2093−2104.
[8] Dai W, Xie D, Lu M, et al. Characterization of white tea metabolome: Comparison against green and black tea by a nontargeted metabolomics approach[J]. Food Research International,2017,96(6):40−45.
[9] Xie D, Dai W, Lu M, et al. Nontargeted metabolomics predicts the storage duration of white teas with 8-C N-ethyl-2-pyrrolidinone-substituted flavan-3-ols as marker compounds[J]. Food Research International,2019,125(11):7209−7218.
[10] 刘鹏, 艾施荣, 杨普香, 等. 非线性流形降维方法结合近红外光谱技术快速鉴别不同海拔的茶叶[J]. 茶叶科学,2019,39(6):715−722. [Liu P, Ai S R, Yang P X, et al. Nonlinear manifold dimensionality reduction methods for quick discrimination of tea at different altitude by near infrared spectroscopy[J]. Tea Science,2019,39(6):715−722. doi: 10.3969/j.issn.1000-369X.2019.06.011 [11] Wang Y J, Li T H, Li L Q, et al. Micro-NIR spectrometer for quality assessment of tea: Comparison of local and global models[J]. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy,2020,237:118403. doi: 10.1016/j.saa.2020.118403
[12] 刘洪林. 基于近红外光谱技术(NIRS)对工夫红茶审评品质客观评价研究[J]. 食品工业科技,2016,37(5):311−315. [Liu H L. Research of evaluation the quality of Congou black tea by near infrared spectroscopy[J]. Science and Technology of Food Industry,2016,37(5):311−315. [13] 李春霖. 基于化学计量学和近红外光谱技术的龙井茶感官及化学品质评价研究[D]. 杭州: 浙江大学, 2019. Li C L. Sensory and chemical quality evaluation of Longjing tea using chemoetrics and near-infrared spectroscopy technique[D]. Hangzhou: Zhejiang University, 2019.
[14] 于英杰, 王琼琼, 王冰玉, 等. 基于高光谱技术的铁观音茶叶等级判别[J]. 食品科学,2014,35(22):159−163. [Yu Y J, Wang Q Q, Wang B Y, et al. Identification of Tieguanyin tea grades based on hyperspectral technology[J]. Food Science,2014,35(22):159−163. doi: 10.7506/spkx1002-6630-201422030 [15] 李晓丽, 魏玉震, 徐劼, 等. 基于高光谱成像的茶叶中EGCG分布可视化[J]. 农业工程学报,2018,34(7):180−186. [Li X L, Wei Y Z, Xu J, et al. EGCG distribution visualization in tea leaves based on hyperspectral imaging technology[J]. Transactions of the Chinese Society of Agricultural Engineering,2018,34(7):180−186. doi: 10.11975/j.issn.1002-6819.2018.07.023 [16] 李瑶. 基于高光谱成像的茶叶品质判别方法研究[D]. 成都: 四川农业大学, 2018. Li Y. A method of distinguishing tea quality based on hyperspectral imaging[D]. Chengdu: Sichuan Agricultural University, 2018.
[17] Ren G, Wang Y, Ning J, et al. Using near-infrared hyperspectral imaging with multiple decision tree methods to delineate black tea quality[J]. Spectrochimica Acta Part A Molecular and Biomolecular Spectroscopy,2020,237:118407. doi: 10.1016/j.saa.2020.118407
[18] Hong Z, He Y. Rapid and nondestructive discrimination of geographical origins of Longjing tea using hyperspectral imaging at two spectral ranges coupled with machine learning methods[J]. Applied Science,2020, 10(3):1173−1184.
[19] 魏玉震. 基于光谱和光谱成像技术的茶叶含水率检测机理和方法研究[D]. 杭州: 浙江大学, 2019. Wei Y Z. Moisture content detection of tea leaves based on spectral and spectral imaging technologies[D]. Hangzhou: Zhejiang University, 2019.
[20] 芦兵, 孙俊, 杨宁, 等. 基于荧光透射谱和高光谱图像纹理的茶叶病害预测研究[J]. 光谱学与光谱分析,2019,39(8):2515−2521. [Lu B, Sun J, Yang N, et al. Prediction of tea disease based on fluorescence transmission spectrum and texture of hyperspectral image[J]. Spectroscopy and Spectral Analysis,2019,39(8):2515−2521. [21] 田欣. 高光谱图像的去噪模型与算法[D]. 长沙: 湖南大学, 2019. Tian X. Models and algorithms for hyperspectral image restoration[D]. Changsha: Hunan University, 2019.
[22] H Martens, S Å Jensen, P Geladi. Multivariate linearity transformation for near-infrared reflectance spectrometry[C]// Proc Nordic Symp on Applied Statistics(O. H. J. Christie, ed.), Stokkand Forlag Publ, Stavanger, Norway, 1983: 208-234.
[23] 郭辉, 彭彦昆, 江发潮, 等. 手持式牛肉大理石花纹检测系统[J]. 农业机械学报,2012,43:207−210. [Guo H, Peng Y K, Jiang F C, et al. Development of conveyable beef-marbling detection system[J]. Transactions of the Chinese Society of Agricultural Machinery,2012,43:207−210. doi: 10.6041/j.issn.1000-1298.2012.03.037 [24] Shaheen H, Agarwal S, Ranjan P. MinMaxScaler binary PSO for feature selection[M]. First International Conference on Sustainable Technologies for Computational Intelligence, 2020: 705-716.
[25] M Dhanoa, S Lister, R Sanderson, et al. The link between multiplicative scatter correction(MSC) and standard normal variate(SNV) transformations of NIR spectra[J]. Journal of Near Infrared Spectroscopy,1995,2(1):43−47.
[26] Saunders C, Stitson M O, Weston J, et al. Support vector machine[J]. Computer Ence,2002,1(4):1−28.
[27] MATLAB中文论坛. MATLAB神经网络30个案例分析[M]. 北京: 北京航空航天大学出版社, 2010. Matlab Chinese Forum. Matlab neural network analysis of 30 cases[M]. Beijing: Beihang University Press, 2010.
[28] Brereton R G, Lloyd G R. Partial least squares discriminant analysis: Taking the magic away[J]. Journal of Chemometrics,2014,28:214−225.
[29] Miguel Pérez-Enciso, Tenenhaus M. Prediction of clinical outcome with microarray data: A partial least squares discriminant analysis(PLS-DA) approach[J]. Human Genetics,2003,112(5-6):581−592.
[30] Sabouri S, Hajrasouliha A, Song Y, et al. Logistic regression[M]. Basic Quantitative Research Methods for Urban Planners, 2020: 15-24.
[31] Allison P D. Logistic regression using the SAS system: Theory and application[M]. SAS Publishing, 1999: 81-90.
 下载:
下载:

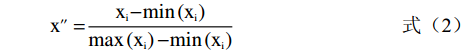
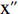
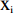
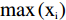
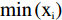



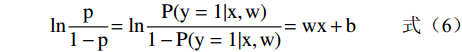




计量
- 文章访问数: 214
- HTML全文浏览量: 63
- PDF下载量: 23
